CourseKata
This is an introduction to the CourseKataData package. For a more comprehensive overview as well as the source code, visit the CourseKataData Github Page. Or, if you are trying to learn more about the contents of the actual data, or how other researchers are using this package, head to the Wiki.
Installation
Download the package directly from this repository using devtools:

Usage
This section details the usage of the functions in the CourseKataData package. #### One and Done The easiest way to get started working with your data is to just download it and run process_data with the path to the zip file (no need to unzip the file first).

If you would like to unzip the file first (which can sometimes be faster), you can also pass the name of the directory to process_data(). If your data was in path/to/downloaded/data.zip and you extracted it to path/to/downloaded/data, then the call should be to the latter path:

When you run process_data(), it will load all of the data and create six data frames (actually tibbles, but they work pretty much the same). These are the names of the tables that are created:
- classes
- responses
- items
- tags
- media_views
- page_views
If there is already an R object with one of these names, you will be given the opportunity to abort the processing or overwrite the existing object. Advanced users can check the R documentation (process_data) to learn how to create these variables in a different environment.
Automatically Merge Multiple Downloads
If you have downloaded multiple data download bundles from CourseKata, don’t worry, this package takes care of merging the files for you. You can specify a vector of zip files or directories to load:

Or, you can put all of the data into a common directory and specify that directory:

Note: this process relies on the fact that the data bundles you download have a consistent format. It may get confused if you reorganize things too much within the downloaded bundles. See more about the structure of the data download and what is in each file in the Data Structure page in the Wiki.
Time Zones
By default the data is parsed using the “UTC” time zone. If you would like to convert the date time data in each table to a different time zone you can specify it. Here is an example with Los Angeles, and another showing how to let your computer decide what time zone you are in:

If you are having trouble with this, see ?timezones for more information.
Splitting Responses
By default, all of the responses in the course are included in the responses table. These responses can be semantically split into three parts: the surveys at the beginning and end of the course, the practice quizzes at the end of each chapter (these are now called review questions, but this function still calls them quizzes because they used to be called that), and the rest of the items in the text. If you would like to split the responses like this, there is a handy split_responses() function that will return a list of three tables:

Piece by Piece
If you would instead like to process only part of the data, you can use the helpful sub-process functions that exist for each of the file types in the data download:
- process_classes()
- process_responses()
- process_items()
- process_tags()
- process_media_views()
- process_page_views()
As with process_data(), each of these functions will accept the path to a CourseKata data bundle zip file or the directory of an extracted zip file, a directory full of bundles, or you can simply supply the name of the file that you want to process with the function.

The classes data file contains information about each class in the data download. However, the other files are specific to each class included in the download. If you want to extract a specific class, you can specify the class_id, which should correspond to the name of the class’s folder in the classes folder of the download. (See more about the structure of the data download and what is in each file in the Data Structure page in the Wiki.)

Export Data
If you are not going to use R to perform your data analysis, you will likely want to export the processed data back to CSV or some other format. Note that many of the base functions in R will have trouble writing the processed data because many of the processed tables have list-columns. A list-column is a column of a data frame where each row / element is itself a list. Here is an example:
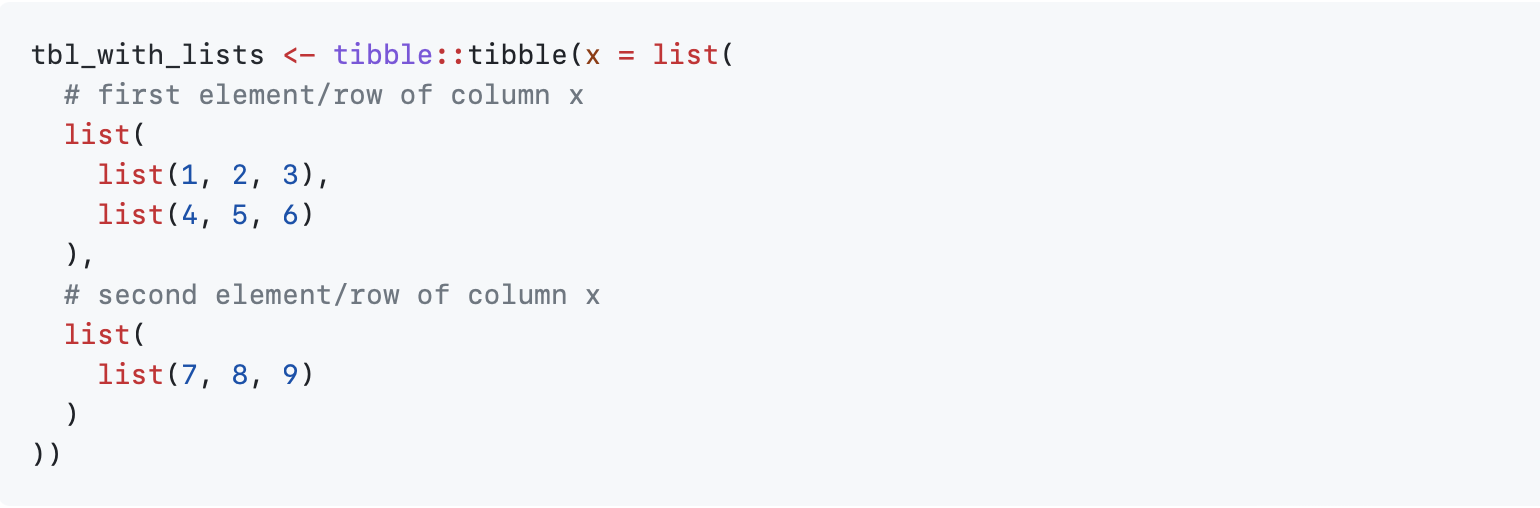
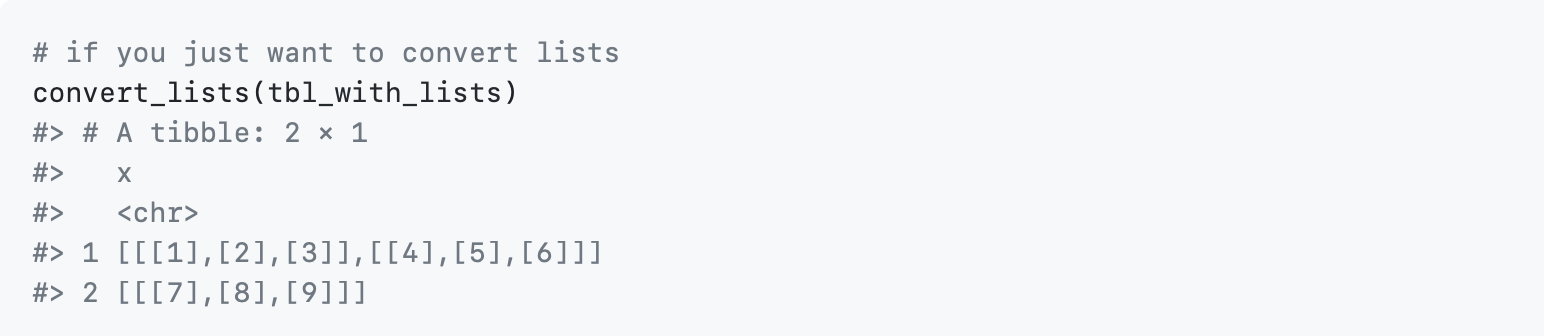
These columns need to be converted back to a format that can be written as a string if you want to export the data to CSV or a similar format that does not have clear rules for exporting lists. For convenience, the convert_lists() function is provided to help conversion, and we load a custom CSV writer to handle this for you:
If you specifically want to export to CSV, we have included a function that can handle this for you. It automatically masks the standard write.csv() with one that will handle these list columns:

Contributing
If you see an issue, problem, or improvement that you think we should know about, or you think would fit with this package, please let us know on our issues page. Alternatively, if you are up for a little coding of your own, submit a pull request:
- Fork it!
- Create your feature branch: git checkout -b my-new-feature
- Commit your changes: git commit -am ‘Add some feature’
- Push to the branch: git push origin my-new-feature
- Submit a pull request :D